
Retour sur expérience : MD5DB.NET | The MD5 Database
Sommaire
MD5DB.NET est un site que j’ai créé en février 2014 qui référence des centaines de millions de hashs MD5 et leur mot équivalent en clair. Voici un rapide retour d’expérience : comment peupler une telle base de données, comment monétiser l’audience et comment assurer un référencement optimal…
Si vous ne savez pas ce qu’est un hash MD5, je vous invite à lire cet article Wikipédia.
Analyse
Soyons clair dès maintenant…. Je ne référence pas des millions de hashs MD5 pour le plaisir de faire avancer la science. Md5db est un moyen de générer de l’audience et de la rentabiliser. En effet les publicités présentes sur ce blog ne rapportent même pas de quoi payer le serveur pour une journée.
Le concept est simple : Un mot possède une empreinte MD5 sensible à la casse facilement déductible avec la fonction MD5() présente dans énormément de langages de programmation. Un hash MD5 peut être issu de plusieurs mots, voire plusieurs chaines de milliers, millions, milliards de caractères.
L’algorithme MD5 n’est pas réversible, sinon il serait un moyen de compression très impressionnant : un hash MD5 est composé de 32 caractères hexadécimaux, jamais plus, jamais moins !

Pour limiter les risques de collisions, nous resterons sur des mots (ou mots de passes…) d’une vingtaine de caractères.
Mon but avec md5db.net est de stocker un très grand nombre de hashs avec leur équivalent en clair et de proposer une navigation et une recherche intuitive et instantanée de cette base de données.
Il existe déjà de nombreux sites qui proposent un tel dictionnaire de données. La liste change régulièrement alors je ne vous propose pas de liens, n’importe quel moteur de recherche peut le faire à ma place.
En revanche, sur la plupart de ces sites vous ne pouvez décoder qu’un seul hash à la fois. Le champ est vérifié et si la chaîne de caractère n’est pas composée de 32 caractères hexadécimaux, ces sites vous retournent généralement une erreur.
Sur MD5DB c’est l’inverse ! Vous pouvez saisir (ou coller) plusieurs lignes qui contiennent chacune un hash. Les caractères non hexadécimaux (les espaces, les quotes, les virgules, les lettres après F et j’en passe…) sont supprimés, même en plein milieu d’un hash. Le site s’occupe de retrouver des hashs valides dans votre chaîne de caractères et vous retourne un résultat dans un tableau. Il est possible d’effectuer une recherche rapide dans le tableau et de l’exporter en CSV. Et vous pouvez rechercher jusqu’à 1000 hashs MD5 en une fois !
Exemple :
Saisie dans le formulaire : [http://md5db.net/decrypt]
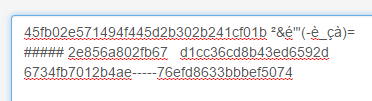
Résultat :
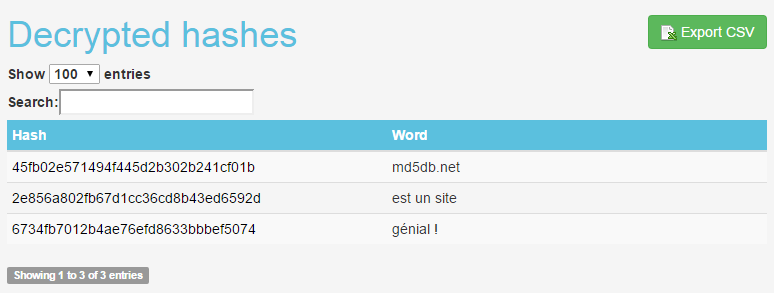
Vous l’aurez compris, l’ergonomie et la facilité d’utilisation sont pour MD5DB un facteur de réussite par rapport à ses semblables.
Choix techniques
Passons maintenant à la partie intéressante : la technique ! Comment stocker, référencer et proposer un accès instantané à des centaines de millions de hashs MD5 sur un serveur dédié d’entrée de gamme ?
La réponse est simple : MySQL et les index !
Avant d’en dire plus, sachez que j’ai volontairement limité la taille des mots à 20 caractères, j’utilise l’encodage ISO-8859-1. Je peuple ma base via deux méthodes :
- Utilisation de dictionnaires de mots anglophones (ainsi que d’autres langues utilisant l’alphabet latin) – Merci Korben & Google
- Création de mots de manière aléatoire, toujours selon les caractères communs de l’alphabet latin
Historique
 J’ai tout d’abord créé le site avec une base SQLite. Connu pour être très léger, c’était mon premier choix. Mais les résultats ont été rapidement décevants. En effet SQLite ne surcharge pas le serveur mais les performances d’écriture et surtout de lecture (recherche d’un hash dans la base) ne sont pas du tout au rendez-vous. SQLite est un produit performant et reconnu, mais il n’est pas adapté à cette utilisation.
J’ai tout d’abord créé le site avec une base SQLite. Connu pour être très léger, c’était mon premier choix. Mais les résultats ont été rapidement décevants. En effet SQLite ne surcharge pas le serveur mais les performances d’écriture et surtout de lecture (recherche d’un hash dans la base) ne sont pas du tout au rendez-vous. SQLite est un produit performant et reconnu, mais il n’est pas adapté à cette utilisation.
 A l’inverse MySQL qui est plus lourd offre une très bonne gestion des index, avec des performances en lecture et en écriture. Les index peuvent être uniques ou non uniques : l’index unique interdit les doublons sur le champ indexé. J’ai utilisé au lancement de md5db.net un index unique sur le champ hash afin d’éviter les doublons.
A l’inverse MySQL qui est plus lourd offre une très bonne gestion des index, avec des performances en lecture et en écriture. Les index peuvent être uniques ou non uniques : l’index unique interdit les doublons sur le champ indexé. J’ai utilisé au lancement de md5db.net un index unique sur le champ hash afin d’éviter les doublons.
Wikipédia défini les index ainsi, cela permet de comprendre comment ils permettent à MySQL d’être aussi rapide avec une aussi grande quantité de données :
Un index est une structure entretenue automatiquement, qui permet de localiser facilement des enregistrements dans un fichier. L'utilisation des index est basée sur l'observation suivante: pour trouver un livre dans une bibliothèque, au lieu d'examiner un par un chaque livre, il est plus rapide de consulter le catalogue où ils sont classés par thème, auteur et titre. Chaque entrée d'un index comporte une valeur extraite des données et un pointeur sur son emplacement d'origine. Un enregistrement peut être ainsi facilement retrouvé en recherchant sa localisation dans l'index.
Source : https://fr.wikipedia.org/wiki/Index_(base_de_donn%C3%A9es)#Principe
La table hashs
Au final, la structure de la table utilisée par md5db est la suivante :
CREATE TABLE IF NOT EXISTS `md5` ( `word` varchar(20) NOT NULL, `hash` char(32) NOT NULL, PRIMARY KEY `hashIndex` (`hash`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
Grâce aux index de MySQL, la recherche de un ou plusieurs hashs dans la table est instantanée. La consommation RAM / Disque / CPU reste raisonnable.
L’utilisation d’API
Même avec l’utilisation de dictionnaires de mots et d’un générateur aléatoire de mots, la base de données ne peut pas contenir tous les hashs MD5 possibles.
Afin d’augmenter les chances de trouver un mot lors d’une recherche, le script utilise les API d’autres sites similaires si le hash MD5 n’est pas trouvé dans la base de données, par exemple : http://md5.gromweb.com/.
Si le mot existe dans une autre base de données, alors le résultat sera ajouté dans la base de données et retourné à l’utilisateur.
Enfin, md5db.net propose son propre système d’API => http://md5db.net/api.
Le référencement : les pages hashes explorer
Principe
L’autre facteur de réussite de md5db.net est un bon référencement (par réussite, comprenez que l’audience du site est rentabilisée). En effet, les hashs sont stockés et l’optimisation de la base de données permet une recherche instantanée, mais si l’audience est faible, cela ne sert à rien.
Il fallait donc un système de navigation parmi les hashs, un système permettant de les afficher – et de les référencer – tous, un système pour les gouverner tous. A l’heure ou j’écris ces lignes, il y a environ 800 millions d’entrées dans la base de données, un affichage sur une seule page n’est pas du tout envisageable.
Il fallait donc découper la navigation selon plusieurs niveaux, notamment selon les premiers caractères des hashs MD5. Un hash MD5 est composé de 32 caractères héxadécimaux :
0 1 2 3 4 5 6 7 8 9 A B C D E F
En filtrant l’affichage des hashs selon les premiers caractères, il est possible de découper la navigation en plusieurs URLs. Il faut alors trouver l’équilibre entre :
- Le nombre de hashs affichés sur une seule page
- Le nombre d’URLs générées
Google impose pour chaque fichier sitemap les limites suivantes : [Source]
- Une taille maximale de 50Mo
- 50 000 URLs
Il n’est cependant pas interdit d’envoyer plusieurs fichiers sitemap.
Un peu de maths
Selon les données suivantes, j’ai choisi d’utiliser 4 niveaux de navigation. Cela représente :
-
16^1 + 16^2 + 16^3 + 16^4 URLs = 69904 URLS (deux fichiers sitemaps suffisent)
-
800 000 000 / 16^4 = environ 12 000 hashs par page
Voici une représentation simplifiée (uniquement les extrémités) de la navigation :
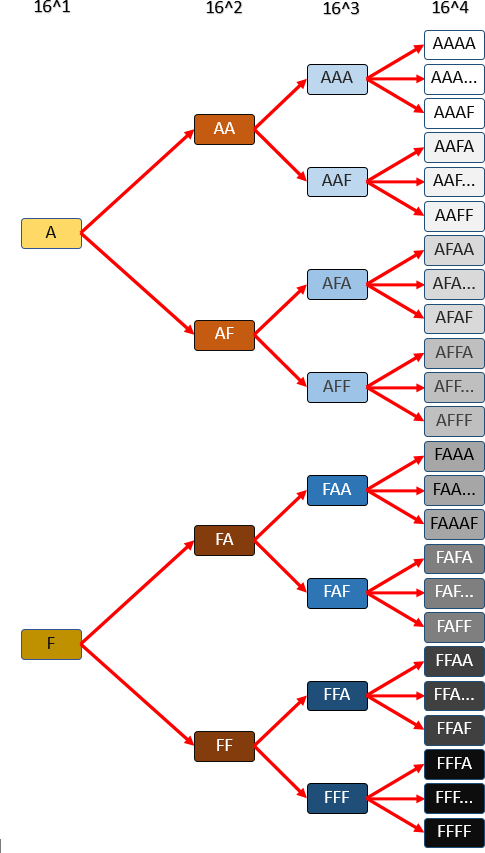
Voici quelques exemples de navigation :
- La liste des hashs qui commencent par 7B09 :
- La liste des hashs qui commencent par 456 :
- La page d’accueil Hashes explorer
Optimisation du référencement
Pas besoin d’être un expert en SEO pour référencer correctement son site web, le référencement naturel se fait tout seul si le site est bien conçu. Ploum a rédigé un article génial à ce sujet !
Sur chacune des pages du module « hashes explorer » et également partout ailleurs sur le site, chaque hash est intégré au sein d’un lien avec la balise <a>, le lien pointe sur une page de visualisation du hash et de son mot équivalent :
<a href="md5db.net/view/HASH">HASH</a>
Optimisation de la vitesse d’affichage
Au lancement du site, lorsque chaque page d’affichage des hashs selon les 4 premiers caractères n’affichait qu’une centaine de lignes, j’effectuais la requête suivante dans la base de données :
SELECT * FROM 'md5' WHERE hash LIKE 'XXXX%' ORDER BY hash
Remplacez XXXX par les 4 premiers caractères des hashs.
L’affichage était assez rapide avec une centaine de hashs. Mais au fur et à mesure du peuplement de la base de données, la vitesse de chargement de la page augmentait dangereusement. C’était un réel problème puisque le temps de chargement est un critère de référencement pour Google. [source 1 – source 2 – source 3]
J’ai donc décidé de mettre en cache ces pages : 65536 (16^4) fichiers sont donc stockés sur le serveur, ces fichiers contiennent la liste des hashs et de leur équivalent dans un tableau PHP sérialisé.
Grossièrement, le code PHP fonctionne ainsi :
Ajout d’un nouveau hash dans le cache
- Le fichier de mise en cache est ouvert et dé-sérialisé dans un tableau PHP
- Le hash et son mot sont ajoutés au tableau PHP
- Le tableau est trié selon les hashs (le tri est très rapide par rapport à la base de données : les tableaux PHP sont stockés en RAM)
- Le tableau PHP est à nouveau sérialisé dans un fichier
$array = unserialize(file_get_contents('XXXX'));
if (!isset($array[$hash]))
{
$array[$hash] = $word;
ksort($array);
file_put_contents('XXXX', serialize($array));
}
Génération d’une page d’affichage des hashs selon les 4 premiers caractères
- Le fichier de mise en cache est ouvert et dé-sérialisé dans un tableau PHP
- Un tableau HTML est généré à partir du tableau PHP
$array = unserialize(file_get_contents('XXXX'));
foreach ($array as $hash => $word)
{
echo "<tr>";
echo "<td><a href='http://md5db.net/view/".$hash."' title='".$hash."'>".$hash."</a></td>";
echo "<td>".$word."</td>";
echo "</tr>";
}
Grâce à cette technique de mise en cache, la base de données n’est pas sollicitée lors de l’affichage des pages « hashes explorer« . L’affichage est instantané, même avec plusieurs milliers de hashs.
Enfin, j’utilise le plugin DataTables afin d’améliorer l’ergonomie utilisateur. Ce plugin permet de paginer un tableau HTML et d’y effectuer une recherche rapide en Javascript. Côté utilisateur, le serveur n’est pas sollicité.
La pub : Google Adsense
Maintenant que le site fonctionne bien, qu’il est rapide, ergonomique et bien référencé, il faut rentabiliser l’audience.
Le choix de la régie de pub a été très rapide : Google Adsense. C’est une régie qui rapporte au coût par clic (CPC), mon audience ne me permettant pas de choisir une régie qui fonctionne au coût pour mille affichages (CPM).
Google Adsense ne propose pas de blocs envahissants (blocs de pubs qui recouvrent le contenu, popups) et c’est pas plus mal ! Les blocs de pubs sont correctement placés à leur place.
J’utilise des bandeau d’annonces différents selon le type de périphérique (mobile / desktop).
Quelques statistiques
 Sur le site
Sur le site
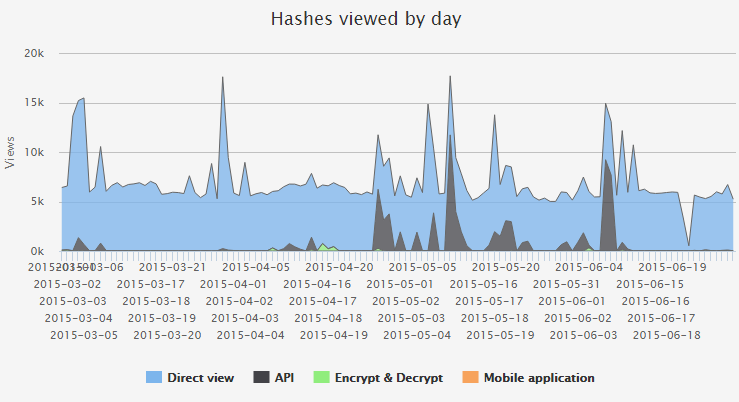
Md5db.net possède une page de statistiques de consultations des hashs en fonction de la provenance (vue directe, décryptage via le formulaire, api…).
La page de statistiques se trouve ici.
Les sitemaps
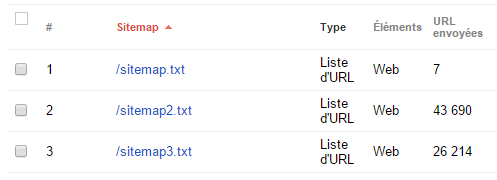
J’expliquais plus haut que Google limite les sitemaps à 50 000 URLs. Le format peut être du XML ou un simple fichier texte. J’utilise 3 sitemaps :
- sitemap.txt : Liste des pages principales du site (encrypt, decrypt, top 1000, api, stats, hashes explorer)
- sitemap2.txt : Liste des pages du « hashes explorer » de /0000 à /9fff
- sitemap3.txt : Liste des pages du « hashes explorer » de /a000 à /ffff
Google accepte correctement ces sitemaps :
Quelques chiffres
Aujourd’hui la base pèse environ 77Go :
mysql> SELECT table_name, ((data_length + index_length) / 1024 / 1024) as "Taille (Mo)" FROM information_schema.TABLES WHERE table_schema = "md5" AND table_name = "md5"; +------------+----------------+ | table_name | Taille (MB) | +------------+----------------+ | md5 | 77108.85062790 | +------------+----------------+ 1 row in set (0.00 sec)
Les fichiers de mise en cache pèsent 45Go :
root@XXXXX:/var/md5_website# du -h dossier_cache 45G dossier_cache
Afin de mesurer l’audience, j’utilise Google Analytics :
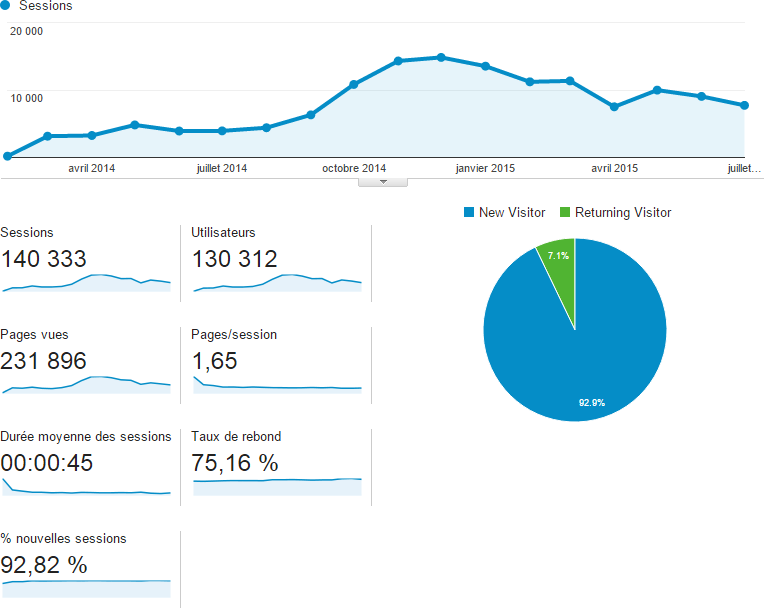
Nous constatons que le taux de rebond est relativement élevé : 75%. Cela signifie que 75% de l’audience ne consulte qu’une seule page lors d’une visite. Nous pouvons interpréter cela de deux manières :
- Les visiteurs ne sont pas intéressés par le contenu du site et partent dès leur arrivée
- Les visiteurs trouvent l’information qu’ils cherchent sur la première page qu’ils consultent (merci le référencement et la mise en cache des résultats)
L’audience se renouvelle constamment puisque 92% des visiteurs n’ont jamais visité le site auparavant.
Enfin, autre donnée importante : la moitié de l’audience provient de périphériques mobiles :
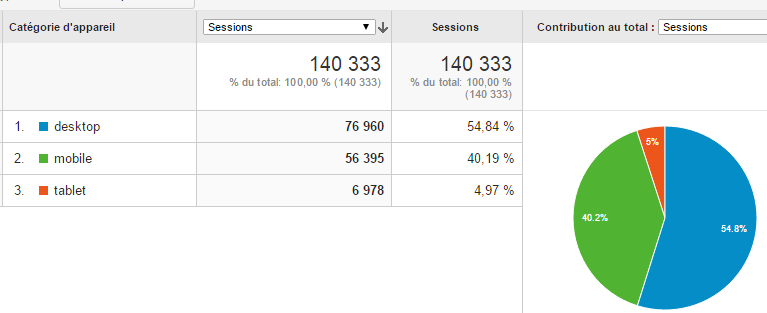
C’est pour cette raison que certains blocs de publicité sont dédiés à l’affichage mobile.
Évolution 1 : Le top 1000 et le compte twitter
Md5db.net comporte une page de classement Top 1000. Dès qu’un hash est décodé ou visionné sur le site, un compteur s’incrémente dans une table de données dédiée.
Cette table de classement utilise les index de MySQL et le top 1000 est mis en cache par le serveur tous les jours, exactement selon le même principe que les pages « hashes explorer ».
Voici la structure de la table « classement » :
CREATE TABLE IF NOT EXISTS `classement` ( `hash` char(32) NOT NULL, `creation` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `vues` int(11) NOT NULL DEFAULT '1', `twitter` int(1) NOT NULL DEFAULT '0', PRIMARY KEY (`hash`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
 De plus, pour maximiser le référencement, j’ai crée un compte Twitter @MD5DBNET qui twitte automatiquement toutes les deux minutes un hash.
De plus, pour maximiser le référencement, j’ai crée un compte Twitter @MD5DBNET qui twitte automatiquement toutes les deux minutes un hash.
Pourquoi toutes les deux minutes ? Parce que la limite de Twitter est de 2400 tweets journaliers, ce qui équivaut à environ un tweet toutes les 2 minutes. [Source]
Le hash qui est tweeté toutes les deux minutes est sélectionné dans la table de classement : c’est le hash qui possède le plus de vues mais qui n’a pas encore été tweeté. Ainsi, si pour un événement quelconque, un hash se retrouve à être plusieurs fois recherché ou décrypté en l’espace de quelques minutes, il sera tweeté en moins de deux minutes.
Decrypt MD5 hash : 8e2c7ff02b269043a47a53ab33583e5e At http://t.co/jkV3XurOWs #md5 #decrypt #hash #md5db
— MD5DB | MD5 DATABASE (@MD5DBNET) 11 Août 2015
Le bilan de cette évolution est mitigé. Je suis convaincu que le Top 1000 est un atout pour le référencement du site, mais le compte twitter n’est pas réellement utile. Personne ne veut suivre un compte qui tweete toutes les 2 minutes 24/7. En revanche, certains tweets sont partagés et favorisés.
Évolution 2 : L’application mobile
 J’ai également crée une application Android MD5DB.NET en juin 2015. L’application permet de chiffrer des mots en MD5 et de les déchiffrer en utilisant la base de données du site.
J’ai également crée une application Android MD5DB.NET en juin 2015. L’application permet de chiffrer des mots en MD5 et de les déchiffrer en utilisant la base de données du site.
Pour l’instant, le bilan de cette application est également mitigé : elle a été téléchargée une cinquantaine de fois en deux mois mais elle n’a pas encore été notée.
Pour conclure…
Md5db.net fonctionne et son objectif est atteint : l’audience est là et elle est rentabilisée. Le défi technique a été captivant. Au fur et à mesure de l’augmentation de l’audience des évolutions ont été nécessaires. Je pense aujourd’hui être arrivé au bout.
Tout ça pour un algorithme qui a plus de 20 ans…


Bonjour,
Très intéressant comme article, surtout la partie technique. Pourquoi ne pas avoir fait le choix d’une flat database (ie. des fichiers texte) plutôt que du MySql ? J’utilise ça sur mon site et ça fonctionne très bien, si l’architecture est pensée en amont. Les performances sont meilleures pour moi que sur une base mysql, surtout quand on commence à dépasser le milliard d’entrées.
Je suis étonné de voir la part de mobiles dans votre audience, notamment parceque les gens qui ont besoin d’une base md5 le font rarement depuis un mobile. Du moins c’est ce que je pensais jusqu’à présent 🙂
Merci pour cet article instructif 😀
Bonjour,
Les fichiers textes sont utilisés pour faire du cache, ce qui permet une rapidité lors de l’affichage en liste des hashs MD5. J’utilise MySQL et ses index pour la rapidité de la recherche parmi les hashs. Je ne sais pas si la recherche serait réellement aussi rapide avec une flat database…
J’ai été également été très étonné de la part d’audience mobile. C’est pour cela que certains blocs de pubs sont dédiés à l’affichage mobile.
Pour avoir moi même un site avec une base de hashs, je peux dire que (dans mon cas) ça a été une évolution niveau rapidité. Je met à peu prèx 1mn à afficher les résultats pour 500 hashs. Après je suis sur un serveur partagé donc moins de ressources.
Crackstation utilise aussi une flat pour ses hashs, et il en a 15 milliards donc c’est assez efficace.
Après quand ça monte je ne sais pas du tout comment on peut faire, notamment cmd5 et md5online qui ont des databases gigantesques.