
Étendre le volume /var à plus de 4Go sur un serveur dédié Debian chez 1and1 avec LVM
Par défaut, le volume logique /var (qui contient le dossier www d’apache) est dimensionné à 4Go sur un serveur dédié loué chez 1and1.
Un oubli de configuration à l’installation du serveur peut mener à des conséquences non négligeables comme l’arrêt du service apache et/ou mysql un beau jour quand le volume sera plein.
Voici la marche à suivre pour étendre à chaud le volume logique.
 LVM
LVM
Les serveurs dédiés chez 1and1 fonctionnent avec Logical Volume Manager (LVM – Gestionnaire de volume logique en français).
LVM est une surcouche logicielle du partitionnement physique créée dans un but de souplesse de manipulation des volumes (équivalents logiques des partitions).
LVM stocke les données à sa manière sur la partition physique, l’administrateur n’a plus de souci à se faire sur l’emplacement physique des données et sur la limitations des 4 partitions principales / étendues.
Toutes les manipulations de volumes peuvent se faire rapidement, à chaud, et surtout sans risques.
LVM se décompose en VolumeGroup, eux même décomposés en Volumes. Généralement, il n’existe qu’un seul VolumeGroup sur une partition et les dossiers /, /var et /home (ou d’autres) sont montés dans des Volumes.
Pour une documentation plus complète de LVM, consultez la doc de debian-facile.org ou celle de deimos.fr.
Le cas d’un serveur dédié Debian chez 1and1
Chez 1and1, un serveur dédié possède par défaut les volumes suivants :
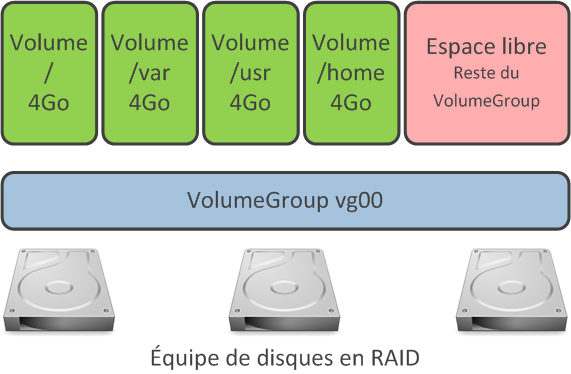
Augmentation du volume /var
![]() Toutes les manipulations sont à faire en root !
Toutes les manipulations sont à faire en root !
Avec cette commande :
df -h
Vous constaterez que le dossier /var fait 4Go.
Vous obtiendrez toutes les informations du VolumeGroup vg00 avec la commande vgdisplay :
vgdisplay -v vg00
Pour chacun des volumes, la taille et le point de montage sont affichés. La taille restante du VolumeGroup est aussi affichée.
![]() Rappel : Toutes les modifications suivantes peuvent se faire à chaud ! Pensez quand même à sauvegarder vos données avant !
Rappel : Toutes les modifications suivantes peuvent se faire à chaud ! Pensez quand même à sauvegarder vos données avant !
Après avoir vérifié la taille disponible dans le VolumeGroup, étendez le volume /var (utilisable dans /dev/vg00/var) avec la commande lvextend (augmentation d’1Go dans cet exemple) :
lvextend -L +1G /dev/vg00/var
L’opération devrait être rapide.
A ce stade, les modifications ne sont pas encore (matériellement) effectuées sur le VolumeGroup.
Si vous n’obtenez pas d’erreur, confirmez l’opération avec la commande resize2fs :
resize2fs /dev/vg00/var
Cette opération prend du temps et applique définitivement les modifications.
L’augmentation du /var d’1Go n’est qu’un exemple et il est possible d’étendre chacun des volumes en respectant la taille disponible dans le VolumeGroup.
La commande lvreduce existe aussi afin de réduire un volume. Consultez la documentation ici.
Cet article a été inspiré de la documentation officielle de 1and1 sur le sujet.

Bonjour Thibaud, j’ai le volume VAR de mon serveur cloud qui est 31gb. Le volume est plein à 95%, existe t-il une commande ou un batch (pour le batch j’ai lu cela sur un article qui est le tient me semble t-il (http://www.techrevolutions.fr/augmenter-le-volume-du-var-devmappervg00-var-sur-un-serveur-dedie-11-et-autres) pour effacer les logs en toute sécurité VIA SSH svp ??
Je cherche à faire de l’espace, car dès que l’on se rapproche des 100% la seule solution (que je connaisse semble l’augmentation du volume et ainsi de suite…) ne peut-on pas tout simplement effacer proprement certaines données ??
Merci beaucoup pour ton aide et ta réponse !
Bonjour Nicolas. Effectivement Techrevolutions a repris une bonne partie de mon article, mais la licence de ce blog les autorise !
Sinon, commence par un petit « df -h » pour avoir un aperçu des volumes montés. Cela te permettra aussi d’identifier le volumgroup et le volume logique qui posent problème.
Si tu as de la place sur ton disque dur, tu peux étendre le groupe et le volume logique, c’est la magie de LVM !
De quels logs parles-tu ? Effacer des logs ne te feras pas gagner une place folle…
Si tu manque de place, il serait judicieux de réduire un autre volume afin d’affecter une éventuelle place supplémentaire à ton /var.
LVM est souple, profitons-en ! N’hésites pas à me donner d’autres détails sur ta configuration si tu veux de l’aide !
Thibaud
Bonjour Thibaud !
Déjà un énorme Merci pour ta réponse rapide et ton aide très ‘précieuse’ cela fait des années que je cherche une solution (2,3 ans) sur google et autres blog sans succès (j’ai l’impression aussi que chaque cas est particulier?).
Lorsque mon volume VAR se remplit et atteint quasi 100%, les sites du serveur ne s’affichent plus ou affichent une erreur (trop de connexion à MySql – en fait le serveur étant plein, la connexion à MySql ne semble plus se faire).
Jusqu’à maintenant mes 2 seules solutions sont :
-redémarrage du serveur pour gagner un tout petit peu de cache, et la commande « yum clean all »
Je pense que ton aide va aider d’autres personnes qui comme moi sont plus dans la partie création de site que gestion du serveur. Néanmoins lorsqu’on a plusieurs sites à héberger, avoir son propre serveur est le plus économique bien que je comprenne parfaitement que l’infogérance est un travail à part qui doit être fait par des professionnels. Seulement beaucoup n’ont pas les moyens…
J’ai exécuté la commande « df -h » et voici le résultat:
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 4.0G 964M 3.1G 24% /
/dev/mapper/vg00-usr 4.0G 1.4G 2.4G 36% /usr
/dev/mapper/vg00-var 31G 24G 5.6G 82% /var
/dev/mapper/vg00-home
4.0G 136M 3.7G 4% /home
none 1000M 8.0K 1000M 1% /tmp
J’ai augmenté hier vg00-var d’environ 5gb (en suivant le tutoriel 1and1 très similaire au tiens).
Par défaut le serveur 1and1 est monté avec 4gb sur vg00-var.
Mes 2 grandes questions sont :
1- Pourquoi est ce que /dev/mapper/vg00-var ne cesse de se remplir ??
2- Y a t-il une solution pour purger ces fichiers et ainsi retomber en dessous des 4GB?
J’ai juste cru comprendre que ce sont des fichiers log sur le serveur qui prennent cette place (24gb ??) pour autant à l’installation des sites sur le serveur tout fonctionnait parfaitement sans que le volume en question ne dépasse les 4gb.
Une dernière chose, l’article de Techrevolutions termine par ceci :
Et voilà ! Mon conseil pour finir : mettez en place un batch qui purgera le volume de temps en temps (pour supprimer les logs par exemple).
cela m’interpelle… c’est peut-être la solution que je recherche??
Ton avis d’expert me serait très précieux !
Merci beaucoup encore pour ton aide !!
Bonjour,
J’ai écrit cet article quand j’était coincé avec un /var à 4Go sur un 1and1. Je ne connaissais pas encore les technos raid et lvm.
J’avais exactement le même problème que toi, MySQL qui ne voulait plus fonctionner pour une raison obscure… J’ai eu besoin de temps pour comprendre d’où venait le problème ! C’est vrai, chaque cas est particulier en terme de configuration… Mais les erreurs sont souvent similaires.
La suppression de fichiers logs n’est pas la première solution que je proposerais… Mais avec un disque dur de 31Go, je pense qu’on ne va pas avoir le choix !
Je te confirme que la plupart des logs sont placés dans le répertoire /var/log. C’est sûrement eux qui remplissent la partition (en plus des données de tes sites).
Ceux d’Apache sont stockées dans /var/log/apache2. Essaie un « ls -lah » pour voir la tailles des fichiers.
Il y’a les logs d’accès (access.log et other_vhosts_access.log) et les logs d’erreurs (error.log)… Bref, Apache crée plusieurs fichiers, tu vas pouvoir faire le ménage du côté de ceux qui ont déjà été compressés en .gz.
Il ne vaut mieux pas les supprimer, mais les vider. Essaie la commande suivante :
for i in *.gz; do echo "" > $i; doneCette commande va boucler sur les fichiers et les vider, un par un.
Commence par ça et refait un petit coup de « df -h » après. Problème réglé !?
Bonjour Thibaud,
encore milles merci pour ton aide en Live !
d’ailleurs si tu arrives à m’aider à résoudre ça, il faudra me faire un mail en privé… au moins que je fasse une donation Paypal.
Bref, en dehors j’ai essayé et voici le résultat :
# ls -lah
total 464K
dr-xr-x— 5 root root 4.0K May 18 03:27 .
dr-xr-xr-x 26 root root 4.0K Jul 30 12:07 ..
-rw——- 1 root root 1.3K Jul 11 2011 anaconda-ks.cfg
drwxr-xr-x 2 root root 4.0K Jul 31 03:40 .autoinstaller
-rw——- 1 root root 880 Jul 31 13:34 .bash_history
-rw-r–r– 1 root root 18 May 20 2009 .bash_logout
-rw-r–r– 1 root root 176 May 20 2009 .bash_profile
-rw-r–r– 1 root root 176 Sep 23 2004 .bashrc
-rw-r–r– 1 root root 29 May 12 15:29 created
-rw-r–r– 1 root root 100 Sep 23 2004 .cshrc
-rw-r–r– 1 root root 8.6K Jul 11 2011 install.log
-rw-r–r– 1 root root 3.1K Jul 11 2011 install.log.syslog
-rw-r–r– 1 root root 128K Jan 8 2013 kmod-e1000e-2.1.4-1.el6.elrepo.x86_64.rpm
-rw-r–r– 1 root root 133K Sep 23 2013 kmod-e1000e-2.5.4-1.el6.elrepo.x86_64.rpm
-rw-r–r– 1 root root 114K Sep 23 2013 kmod-igb-5.0.5-1.el6.elrepo.x86_64.rpm
-rw-r–r– 1 root root 0 May 14 12:17 .odbc.ini
drwxr-xr-x 6 root root 4.0K Jul 31 03:38 parallels
drwxr—– 3 root root 4.0K May 14 12:18 .pki
-rw——- 1 root root 1.0K May 14 12:15 .rnd
-rw-r–r– 1 root root 129 Dec 3 2004 .tcshrc
# for i in *.gz; do echo « » > $i; done
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 4.0G 964M 3.1G 24% /
/dev/mapper/vg00-usr 4.0G 1.4G 2.4G 36% /usr
/dev/mapper/vg00-var 31G 24G 5.5G 82% /var
/dev/mapper/vg00-home
4.0G 136M 3.7G 4% /home
none 1000M 8.0K 1000M 1% /tmp
———————–
on dirait que quelque chose d’autre rempli le volume IoI;;;
vu la taille des fichiers avec la commande # ls -lah
c’est ce que tu disais dans la 1ere réponse… les logs ne sont pas si lourds que ça en fait… ! (464k)
Merci encore pour ton aide !
Tu étais bien dans le dossier /var/log/apache2 ? Ton serveur web est-il Apache2 au moins ? Quelle est ta distribution ?
De manière plus générale, tu peux utiliser ncdu (http://dev.yorhel.nl/ncdu) pour connaitre l’utilisation de tes disques. Installe le avec apt-get ou yum selon ta distrib.
yum install ncduapt-get install ncdu
ncdu
Tu pourras te balader dans l’arborescence (via SSH bien entendu) et identifier les répertoires et fichiers volumineux… Le scan du disque dur peut être un peu long…
Il n’est pas question de donation paypal ou d’une quelconque rétribution, nous faisons simplement vivre ce blog. =)
Arff – quel idiot j’aurai du commencé par ça…
j’ai un CentOS 6.5 (Final)comme OS (comme beaucoup)
je vais essayer d’installer -ncdu- et te dire ce qui en sort.
Merci toujours !! J’apprécie énormément cette aide !
Bonjour Thibaud
j’ai pu installer NCDU grâce a tes conseils (et commandes) merci beaucoup pour cela aussi!
cela me donne ceci :
80.0MiB [##########] /parallels
140.0kiB [ ] kmod-e1000e-2.5.4-1.el6.elrepo.x86_64.rpm
132.0kiB [ ] kmod-e1000e-2.1.4-1.el6.elrepo.x86_64.rpm
120.0kiB [ ] kmod-igb-5.0.5-1.el6.elrepo.x86_64.rpm
12.0kiB [ ] install.log
8.0kiB [ ] /.pki
8.0kiB [ ] /.autoinstaller
4.0kiB [ ] install.log.syslog
4.0kiB [ ] anaconda-ks.cfg
4.0kiB [ ] .rnd
4.0kiB [ ] .bash_history
4.0kiB [ ] .bashrc
4.0kiB [ ] .bash_profile
4.0kiB [ ] .tcshrc
4.0kiB [ ] .cshrc
4.0kiB [ ] created
4.0kiB [ ] .bash_logout
4.0kiB [ ] *.gz
0.0 B [ ] .odbc.ini
Ensuite en utilisant la commande : « ncdu -x / »
j’obtiens ce résultat :
568.5MiB [##########] /lib
112.5MiB [# ] /boot
80.5MiB [# ] /root
27.0MiB [ ] /etc
20.6MiB [ ] /lib64
12.0MiB [ ] /sbin
6.5MiB [ ] /bin
e 48.0kiB [ ] /lost+found
8.0kiB [ ] /.pki
e 4.0kiB [ ] /srv
e 4.0kiB [ ] /selinux
e 4.0kiB [ ] /opt
e 4.0kiB [ ] /mnt
e 4.0kiB [ ] /media
e 4.0kiB [ ] /cgroup
e 4.0kiB [ ] /archives
e 4.0kiB [ ] /.spamassassin
4.0kiB [ ] wdcollect.service
4.0kiB [ ] monit.service
4.0kiB [ ] migration.log
> 0.0 B [ ] /var
> 0.0 B [ ] /usr
> 0.0 B [ ] /tmp
> 0.0 B [ ] /sys
> 0.0 B [ ] /proc
> 0.0 B [ ] /home
> 0.0 B [ ] /dev
0.0 B [ ] .autorelabel
0.0 B [ ] .autofsck
mais … arf… je vois le volume VAR à 0.0 B et maintenant je ne vois pas comment avancer plus loin… une suggestion Aurais tu une suggestion s’il te plaît ? Merci beaucoup par avance !
C’est bizarre… Les résultats de NCDU ne sont pas en cohérence avec ceux de « df -h ». Si le /lib fait réellement 585Mo, essaie de faire le ménage à l’intérieur (fichiers logs…).
Et dans /tmp ? Il est vide normalement…
Bonjour Thibaud, encore merci pour ton aide, juste pour clôturer ce post, je t’annonce que je viens ENFIN de résoudre mon problème de serveur moi-même. Pour infos et pôur conseils (si cela peut aider d’autres personnes qui sont dans la situation où j’étais) voici ce qui remplissait mon serveur :
-error_logs (dans le dossier protégé) statistics des nom de domaine.
( 16gb).
-d’autres logs qui eux peuvent s’effacer manuellement via Plesk (ou Cpanel si vous l’avez) depuis l’interface du nom de domaine (websites & domain) => affiché les options supplémentaires puis cliquer sur l’icone : log.
On peut nettoyer (et/ou télécharger) ceux en .processed
C’est aussi par ici que l’on peut lire le fichier error_log (hors console via SSH).
Déjà avec ça… j’ai libéré 17GB et en prime instauré le -logrotate- sur daily !! Pour arrêter ce remplissage quasi inutile.
Enfin… il y avait 6GB de remplissage avec des fichiers _sess (session php) dans le dossier PHP justement.
Une bonne commande à fait le ménage (cela prend environ 5-6 heures pour 6gb)
la commande :
# find /var -size +20000k -exec du -h {} \;
m’a bien aidé à diagnostiquer tout ça… elle a aussi mis en lumière une base de donnér corrompue sur l’un de mes sites.
Cette commande peut-être modifié avec la taille de votre choix :
ex:
# find /var -size +4000k -exec du -h {} \;
ce qui m’a permit de voir le problème avec le nombre -enorme- de fichiers de session php.
Bien sur le listing est beaucoup plus long avec une recherche de fichier de taille plus petite.
Enfin voilà… après réparation de certaines tables, et la maintenance de base. Le serveur est revenu à 10% d’utilisation de la partition VAR (ce qui correspond aux données, et fichiers de mes sites à peu près).
Merci encore pour ton aide de départ !
Très bonne continuation à toi !!
Bonjour, vous allez me prendre pour un nul car 6 ans après votre post, il m’arrive exactement la même chose sur un serveur dédié 1&1 (maintenant Ionos). Cela ne m’était jamais encore arrivé mais il me semble que j’ai la même problématique mais tout au démarrage de mon projet de migration. J’ai déjà réinitialiser le serveur 3 ou 4 fois maintenant en prenant soin à chaque fois de partitionner les volumes de manière à ce que le dossier /var ne soit plus limité. Je tourne sous centos 7 avec une installation de plesk. Dès que je transfert mes dossiers de sites web via File zilla, j’ai l’impression que le serveur commence à faire des choses sans que je lui demande quoi que ce soit. Je dois hébergé 3 sites dont un très gros projet, d’où l’importance d’avoir un serveur dédié. Mais on m’a vendu cette formule avec plesk que je connais bien et me stipulant que je n’aurais pas de problème à gérer des commandes SSH (que je connais beaucoup moins bien étant donné que ce n’est pas ma spécialité). Franchement je ne sais plus quoi faire car ça fait maintenant presque 3 semaines que j’essaye en vain d’installer 3 sites qui étaient hébergés sur des mutualisés et qui ne prennent pas tant de place que ça. J’ai 1 terra octet de disque et au bout de 3 sites web, le serveur plante. Je ne comprends plus rien. J’ai lu votre discussion et j’ai le même problème avec /dev/mapper/vg00-var qui est plein. Mon probème maintenant c’est que lors de ma dernière réinitialisation du serveur, j’ai effectué une augmentation des volumes de partition sur var en lui attribuant 100% du disque. Et du coup, je ne peux absolument pas augmenter le volume /dev/mapper/vg00-var car il n’y a plus d’espace disponible. Je suis perdu car je veux bien encore une fois réinitialiser le serveur et tout réinstaller mais comme mes dossiers de sites sont en local, ça prend à chaque fois entre 10 et 15 heures pour transférer un site. Je suis en plein début de burnout car quand j’appel le service client Ionos, à chaque fois je tombe sur un agent différent qui me donne un nouveau son de cloche (notemment le dernier qui m’avait conseillé d’attribuer 100% de la mémoire à var donc j’ai fait cette commande « lvextend -l +100%FREE /dev/vg00/var » avant de recommencer pour le nième fois tout le processus d’installation des domaines et de migration des données. Je suis épuisé ce matin car j’ai passé encore la nuit dessus après avoir transférer le dernier site qui au bout des trois quarts du transfert via Filezilla a fait tombé plesk et tous les autres sites que j’avais pourtant super bien paramétrés enfin… Du coup, il ne me reste plus que quelque jours avant de décider d’être satisfait ou remboursé car je sent que je me suis bien fait roulé dans la farine. Si vous avez une solution avant que je prenne ma décision finale, j’en serait plus que content car là je suis à bout de mes ressources physiques et psychologiques. Merci d’avance.